



O crescimento acelerado das aplicações com arquiteturas de microsserviços e distribuição em nuvens exigiu que a observabilidade ganhasse destaque nos últimos anos, apesar de não se tratar de um conceito novo.
Mais do que apenas se preocupar com a disponibilidade, a observabilidade diz respeito à exposição de dados e ao fácil acesso às informações. Algo extremamente importante quando há necessidade de visualizar como as interações entre microsserviços estão se apresentando: como falham, quando não ocorrem como esperado ou não deveriam ocorrer.
O monitoramento é fundamental para que se tenha uma ideia geral da saúde dos sistemas, porém a observabilidade vai além e tem como objetivo fornecer dados relevantes sobre o comportamento das aplicações. Observabilidade é a capacidade de inferir condições internas de um sistema com base em suas saídas externas.
Resiliência e os desafios da TI tradicional
O modelo tradicional de TI foi concebido com o objetivo de sustentar sistemas, buscando sua estabilidade e disponibilidade, sendo as aplicações construídas de maneira centralizada. Porém este modelo possui diversas fragilidades e impõe grande dificuldade para realização de mudanças, algo quase que imprescindível atualmente.
Nesse modelo de gestão, que busca manter um CMDB extenso e quase estático, muita energia é despendida com o objetivo de antever problemas e agir apenas caso todas as consequências estejam mapeadas e se houver alguém para culpar quando essas falhas acontecerem.
E claro, problemas sempre acontecem, certo? Afinal, um modelo que represa mudanças faz com que estas aconteçam em blocos, em condições não testadas e não testáveis, além de ocorrerem em janelas de publicação nas quais as pessoas estão menos disponíveis.
Com isso, a entrega de um release de software em uma gestão de TI tradicional é sempre algo imprevisível e passível de falhas recorrentes o que, por sua vez, acaba tendo como consequência a tomada de decisões que pioram ainda mais esse cenário, criando um círculo vicioso de difícil superação.
Entretanto, ao longo dos últimos anos, a área de tecnologia vem mudando em uma velocidade espantosa e várias ferramentas e abordagens vêm surgindo no mercado com propósito de auxiliar na construção de arquiteturas mais otimizadas e, acima de tudo, resilientes.
E a resiliência de um sistema moderno é garantida pela volatilidade de suas partes: stacks de tecnologias onipresentes (como kubernetes e containers) permitem estratégias de baixo custo que trabalham para simplificar a automação de muitas tarefas rotineiras.
Nesse contexto, o papel da TI passa a ser o de prover plataformas nas quais times de produtos possam ter total controle, visibilidade e responsabilidade compartilhada de suas entregas. Sendo possível trabalhar dentro de fronteiras seguras, mas em uma jornada completamente “self-service”. É aí que a observabilidade ganha importância.
Observabilidade como solução
A observabilidade é um conceito muito importante não apenas para quem trabalha na área de infraestrutura de TI, mas sobretudo para os times de produto que entregam releases de software. É por meio dela que é possível identificar problemas que nos mostram como os serviços das aplicações estão interagindo e se comunicando uns com os outros. Em um ambiente com esteiras de entrega contínua (onipresentes onde há prática e cultura DevOps) isto significa que quem entregou uma mudança pode acompanhar imediatamente seu resultado, comparar com o comportamento esperado e, se for o caso, revertê-la.
Afinal, toda a cadeia que vai desde o commit de código, passando pela construção e testes na esteira e terminando em eventual entrega do release precisa ser monitorada, gerenciada e controlada. Somente dessa forma, caso aconteça qualquer falha, é possível que o autor da mudança possa intervir para determinar sua causa e corrigi-la o mais rápido possível.
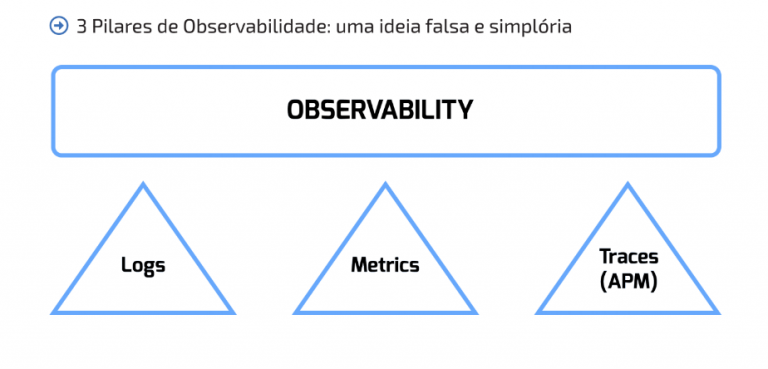
O engodo dos três pilares da TI tradicional
A monitoração de uma TI tradicional se apoia tipicamente sobre três pilares:
- Logs: registro textuais das atividades que ocorreram em um determinado momento. Essa atividade pode ser dos servidores da sua aplicação ou uma ação desencadeada por um usuário, por exemplo. São uma boa forma de auxiliar na resolução de problemas que o desenvolvedor é capaz de antever, mas não impedir.
- Métricas: são valores medidos periodicamente que mostram um total ou percentual de falha de funcionalidades da sua aplicação ou servidores. Com a construção de séries temporais deste tipo aprende-se sobre o comportamento e saúde dos sistemas.
- Tracing: são uma forma de acompanhar todo o fluxo de execução de um sistema distribuído. Cada trace possui uma identificação e uma marcação de tempo. Quando bem implantada, uma estratégia de tracing distribuído, traz à tona uma visão das dependências e comportamento de um sistema em tempo de execução, além de revelar o quanto o cadastro de ICs no CMDB está defasado.
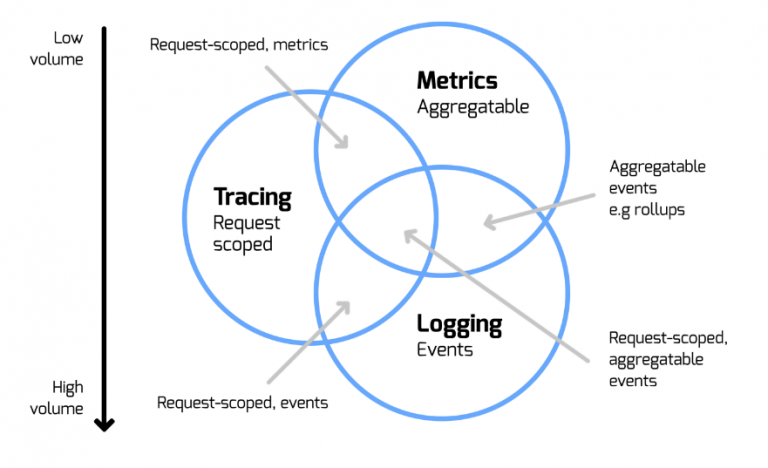
Porém, esses dados são coletados e analisados de forma completamente desconexa e com ferramentas separadas. A TI tradicional abdica de todo o contexto do evento e relega “ao leitor” a missão, praticamente impossível, de recompor as circunstâncias a partir destes dados.
No mais, encontramos alguns problemas com relação a esses elementos, como por exemplo:
- Embora seja possível padronizar e estruturar seus logs, pouco pode ser feito para saídas de logs de código de terceiros. Por isso, em geral, na prática recebemos pouca informação qualificada em logs;
- Logs podem ficar espalhados em um conjunto razoável de arquivos com rotação e formatos particulares. Assim, ajustar uma configuração de coleta que inclua todos os logs pertinentes é um desafio à parte, bem como descobrir quais origens de logs devem compor uma coleção pertinente às pesquisas na resolução de problemas em um sistema distribuído;
- O custo de lidar com logs pode aumentar significativamente com o tempo e são muito comuns histórias do orçamento anual sendo consumido em um único mês;
- Se encaradas como atribuição de times de operação, as métricas coletadas serão apenas higiênicas, contribuindo de fato muito pouco para a compreensão do comportamento dos sistemas em si, no máximo servindo de alerta para alguma degradação ou pico inesperado;
- Métricas são desprovidas de contexto adicional. Sendo assim, pouco auxiliam na identificação da raiz dos problemas que acusam;
- Tracing depende de amostragem e nem sempre as formas disponíveis para selecionar uma amostra são razoáveis. Para piorar as ferramentas comerciais que entregam tracing de qualidade costumam ser muito caras;
Porém, quando falamos de observabilidade, é desejável que todos esses dados coletados sejam analisados dentro do contexto dos eventos, pois logs, métricas e traces, apesar de serem componentes essenciais, perdem quase todo seu valor quando dissociados. Assim, é fundamental perseguir modelos e soluções que preservem este valor e não apenas a capacidade de armazenagem de uma quantidade bruta de dados.
O caminho para a evolução dos negócios
Um modelo de gestão de TI que tem como único objetivo estabilidade e disponibilidade dos sistemas em detrimento de sua capacidade de reação e da entrega de valor representa um atraso para qualquer organização. É imperativo abrir o caminho para uma TI cloud-native, responsiva, observável e resiliente. A boa notícia é que existem estratégias dinâmicas, baseadas ações curtas de resultados rápidos e mensuráveis, que são capazes de conduzir esta transformação sem disrupção operacional.
Com a transição para cloud-native é possível reduzir de forma considerável a quantidade de ICs que devem ser mantidos por processos tradicionais, criando novas categorias com registro e aprovação automáticos em seu ciclo de vida, ou mesmo ICs que são extremamente voláteis e descartáveis.
Implantar uma cultura que tenha como prioridades a responsabilidade compartilhada pelas entregas, maior visibilidade do comportamento dos sistemas, modelos de melhoria contínua e a busca incessante por automação está no coração das práticas de DevSecOps, nas quais testes e entrega de releases de software são apenas parte da solução. Observabilidade passa a ser um componente crítico, portanto, de uma TI moderna.
Gostou do nosso conteúdo? Quer saber mais sobre observabilidade e como ela pode ajudar os seus negócios? Fale com um dos nossos especialistas! Teremos prazer em ajudá-lo.
Avalie o nível de adoção e maturidade DevOps na sua empresa e entenda os pontos fortes, fracos, lacunas e oportunidades de aprimoramento.



